Introduction
Content based image retrieval (CBIR) is still an active research field. There are a number of approaches available to retrieve visual data from large databases. But almost all the approaches require an image digestion in their initial steps. Image digestion is describing an image using low level features such as color, shape, and texture while removing unimportant details. Color histograms, color moments, dominant color, scalable color, shape contour, shape region, homogeneous texture, texture browsing, and edge histogram are some of the popular descriptors that are used in CBIR applications. Bag-Of-Feature (BoF) is another kind of visual feature descriptor which can be used in CBIR applications. In order to obtain a BoF descriptor, we need to extract a feature from the image. This feature can be any thing such as SIFT (Scale Invariant Feature Transform), SURF (Speeded Up Robust Features), and LBP (Local Binary Patterns), etc.
You can find a brief description of BoF, SIFT, and how to obtain BoF from SIFT features (BoF-SIFT) with the source code from this article. BoF-SIFT has been implemented using OpenCV 2.4 and Visual C++ (VS2008). But you can easily modify the code to work with any flavor of C++. You can write the same code yourself if you go through a few OpenCV tutorials.
If you are a developer of CBIR applications or a researcher of visual content analysis, you may use this code for your application or for comparing with your own visual descriptor. Further, you can modify this code to obtain other BoF descriptors such as BoF-SURF or BoF-LBP, etc.
Background
BoF and SIFT are totally independent algorithms. The next sections describe SIFT and then BoF.
SIFT - Scale Invariant Feature Transform
Point like features are very popular in many fields including 3D reconstruction and image registration. A good point feature should be invariant to geometrical transformation and illumination. A point feature can be a blob or a corner. SIFT is one of most popular feature extraction and description algorithms. It extracts blob like feature points and describe them with a scale, illumination, and rotational invariant descriptor.
The above image shows how a SIFT point is described using a histogram of gradient magnitude and direction around the feature point. I'm not going to explain the whole SIFT algorithm in this article. But you can find the theoretical background of SIFT from Wikipedia or read David Lowe's original article regarding SIFT. I recommend to read this blog post for those with less interest in mathematics.
Unlike color histogram descriptor or LBP like descriptors, SIFT algorithm does not give an overall impression of the image. Instead, it detects blob like features from the image and describe each and every point with a descriptor that contains 128 numbers. As the output, it gives an array of point descriptors.
CBIR needs a global descriptor in order to match with visual data in a database or retrieve the semantic concept out of a visual content. We can use the array of point descriptors that yields from the SIFT algorithm for obtaining a global descriptor which gives an overall impression of visual data for CBIR applications. There are several methods available to obtain that global descriptor from SIFT feature point descriptors, and BoF is one general method that can be used to do the task.
Bag-Of-Feature (BoF) Descriptor
BoF is one of the popular visual descriptors used for visual data classification. BoF is inspired by a concept called Bag of Words that is used in document classification. A bag of words is a sparse vector of occurrence counts of words; that is, a sparse histogram over the vocabulary. In computer vision, a bag of visual words of features is a sparse vector of occurrence counts of a vocabulary of local image features.
BoF typically involves in two main steps. First step is obtaining the set of bags of features. This step is actually an offline process. We can obtain set of bags for particular features and then use them for creating BoF descriptor. The second step is we cluster the set of given features into the set of bags that we created in first step and then create the histogram taking the bags as the bins. This histogram can be used to classify the image or video frame.
Bag-of_Features with SIFT
Let's see how can we build BoF with SIFT features.
- Obtain the set of bags of features.
- Select a large set of images.
- Extract the SIFT feature points of all the images in the set and obtain the SIFT descriptor for each feature point that is extracted from each image.
- Cluster the set of feature descriptors for the amount of bags we defined and train the bags with clustered feature descriptors (we can use the K-Means algorithm).
- Obtain the visual vocabulary.
- Obtain the BoF descriptor for given image/video frame.
- Extract SIFT feature points of the given image.
- Obtain SIFT descriptor for each feature point.
- Match the feature descriptors with the vocabulary we created in the first step
- Build the histogram.
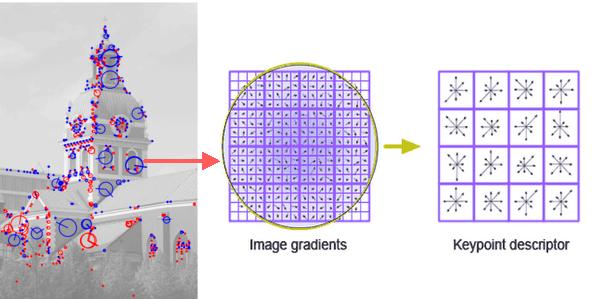
The following image shows the above two steps clearly. (The image has been taken from http://www.sccs.swarthmore.edu/users/09/btomasi1/tagging-products.html)

Using the Code
With OpenCV, we can implement BoF-SIFT with just a few lines of code. Make sure that you have installed OpenCV 2.3 or higher version and Visual Studio 2008 or higher. The OpenCV version requirement is a must but still you may use other C++ flavors without any problems.
The code has two separate regions that are compiled and run independently. The first region is for obtaining the set of bags of features and the other region for obtaining the BoF descriptor for a given image/video frame. You need to run the first region of the code only once. After creating the vocabulary, you can use it with the second region of code any time. Modifying the code line below can switch between the two regions of code.
#define DICTIONARY_BUILD 1 // set DICTIONARY_BUILD to 1 for Step 1. 0 for step 2
Setting the DICTIONARY_BUILD constant to 1 will activate the following code region.
#if DICTIONARY_BUILD == 1
char * filename = new char[100];
Mat input;
vector<KeyPoint> keypoints;
Mat descriptor;
Mat featuresUnclustered;
SiftDescriptorExtractor detector;
for(int f=0;f<999;f+=50){
sprintf(filename,"G:\\testimages\\image\\%i.jpg",f);
input = imread(filename, CV_LOAD_IMAGE_GRAYSCALE); detector.detect(input, keypoints);
detector.compute(input, keypoints,descriptor);
featuresUnclustered.push_back(descriptor);
printf("%i percent done\n",f/10);
}
int dictionarySize=200;
TermCriteria tc(CV_TERMCRIT_ITER,100,0.001);
int retries=1;
int flags=KMEANS_PP_CENTERS;
BOWKMeansTrainer bowTrainer(dictionarySize,tc,retries,flags);
Mat dictionary=bowTrainer.cluster(featuresUnclustered);
FileStorage fs("dictionary.yml", FileStorage::WRITE);
fs << "vocabulary" << dictionary;
fs.release();
You can find what each line of code does by going through the comments above the line. As a summary, this part of code simply reads a set of images from my hard disk, extracts SIFT feature and descriptors, concatenates them, clusters them to a number of bags (dictionarySize), and then produces a vocabulary by training the bags with the clustered feature descriptors. You can modify the path to the images and give your own set of images to build the vocabulary.
After running this code, you can see a file called dictionary.yml in your project directory. I suggest you open it with Notepad and see how the vocabulary appears. It may not make any sense for you. But you can get an idea about the structure of the file which will be important if you work with OpenCV in future,
If you run this code successfully, then you can activate the next section by setting DICTIONARY_BUILD to 0. Here onwards, we don't need the first part of the code since we already obtained a vocabulary and saved it in a file.
The following part is the next code section which achieves the second step.
#else
Mat dictionary;
FileStorage fs("dictionary.yml", FileStorage::READ);
fs["vocabulary"] >> dictionary;
fs.release();
Ptr<DescriptorMatcher> matcher(new FlannBasedMatcher);
Ptr<FeatureDetector> detector(new SiftFeatureDetector());
Ptr<DescriptorExtractor> extractor(new SiftDescriptorExtractor);
BOWImgDescriptorExtractor bowDE(extractor,matcher);
bowDE.setVocabulary(dictionary);
char * filename = new char[100];
char * imageTag = new char[10];
FileStorage fs1("descriptor.yml", FileStorage::WRITE);
sprintf(filename,"G:\\testimages\\image\\1.jpg");
Mat img=imread(filename,CV_LOAD_IMAGE_GRAYSCALE);
vector<KeyPoint> keypoints;
detector->detect(img,keypoints);
Mat bowDescriptor;
bowDE.compute(img,keypoints,bowDescriptor);
sprintf(imageTag,"img1");
fs1 << imageTag << bowDescriptor;
fs1.release();
#endif
In this section, SIFT features and descriptors are calculated for a particular image and we match each and every feature descriptor with the vocabulary we created before.
Ptr<DescriptorMatcher> matcher(new FlannBasedMatcher);
This line of code will create a matcher that matches the descriptor with a Fast Library for Approximate Nearest Neighbors (FLANN). There are some other types of matchers available so you can explore them yourself. In general, an approximate nearest neighbor matching works well.
Finally, the code outputs the Bag Of Feature descriptor and saves in a file with the following code line.
fs1 << imageTag << bowDescriptor;
This descriptor can be used to classify the image for several classes. You may use SVM or any other classifier to check the discriminative power and the robustness of this descriptor. On the other hand, you can directly match BoF descriptors to different images in order to measure similarity.
Points of Interest
I found that this code can easily be converted into a BoF implementation of any other feature such as BoF-SURF, BoF-ORB, BoF-Opponent-SURF and BoF-Opponent-SIFT, etc.
You can find C++ and OpenCV source codes of implementations of both BoF-SURF, BoF-ORB in the following link:
Changing the lines below can get the BoF descriptor with any other type of feature.
SiftDescriptorExtractor detector;
Ptr<FeatureDetector> detector(new SiftFeatureDetector());
Ptr<DescriptorExtractor> extractor(new SiftDescriptorExtractor);
The latest versions of OpenCV include many feature detection and description algorithms so you can apply those algorithms modifying this code and determine the best method for your CBIR application or research.

