Introduction
This is the 4th part of my proposed series of articles on TPL. Last time, I introduced Parallel For and Foreach, and covered this ground:
- Parallel For/Foreach
- Creating a Simple Parallel For/Foreach
- Breaking and Stopping a Parallel Loop
- Handling Exceptions
- Cancelling a Parallel Loop
- Partitioning for Better Performance
- Using Thread Local Storage
This time, we are going to be looking at how to use Parallel LINQ, or PLINQ as it is better known. We shall also be looking at how to do the usual TPL like things such as Cancelling and dealing with Exceptions, as well as that we shall also look at how to use custom Partitioning and custom Aggregates.
Article Series Roadmap
This is article 4 of a possible 6, which I hope people will like. Shown below is the rough outline of what I would like to cover:
- Starting Tasks / Trigger Operations / ExceptionHandling / Cancelling / UI Synchronization
- Continuations / Cancelling Chained Tasks
- Parallel For / Custom Partitioner / Aggregate Operations
- Parallel LINQ (this article)
- Pipelines
- Advanced Scenarios / v.Next for Tasks
Now, I am aware that some folks will simply read this article and state that it is similar to what is currently available on MSDN, and I in part agree with that, however there are several reasons I have chosen to still take on the task of writing up these articles, which are as follows:
- It will only really be the first couple of articles which show similar ideas to MSDN, after that I feel the material I will get into will not be on MSDN, and will be the result of some TPL research on my behalf, which I will be outlining in the article(s), so you will benefit from my research which you can just read... Aye, nice
- There will be screen shots of live output here which is something MSDN does not have that much of, which may help some readers to reinforce the article(s) text
- There may be some readers out here that have never even heard of Task Parallel Library so would not come across it in MSDN, you know the old story, you have to know what you are looking for in the first place thing.
- I enjoy threading articles, so like doing them, so I did them, will do them, have done them, and continue to do them.
All that said, if people having read this article, truly think this is too similar to MSDN (which I still hope it won't be) let me know that as well, and I will try and adjust the upcoming articles to make amends.
Table Of Contents
Anyway, what I am going to cover in this article is as follows:
As most .NET developers are now aware, there in inbuilt support for querying data inside of .NET, which is known as Linq (Language Integrated Query AKA Linq), which comes in several main flavours, Linq to objects, Linq to SQL/EF and LINQ to XML.
We have all probably grown to love writing things like this in our everyday existence:
(from x in someData where x.SomeCriteria == matchingVariable select x).Count();
Or:
(from x in peopleData where x.Age > 50 select x).ToList();
Which is a valuable addition to the .NET language, I certainly could not get by without my Linq. The thing is the designers of TPL have thought about this and have probably seen a lot of Linq code that simply loops through looking for a certain item, or counts the items where some Predicate<T> is met, or we perform some aggregate such as the normal Linq extension methods Sum(), Average(), Aggregate(), etc.
Now it turns out that when we are simply iterating over the results of a simple query where we are trying to match a Predicate<T>,that this is quite suited to parallelism. Some of the other areas are not as simple (at least not in my opinion), but they are still possible, and thankfully the TPL designers have included a way to do all those things when using PLinq.
As with standard Linq, most of the PLinq functionality is delivered through extension methods, which are mainly available for the ParallelQuery and ParallelEnumerable classes. Which offer many of the familiar Linq extension methods. It should be noted that using PLinq does not guarantee that the work will be done quicker, it just means it will offer some level of asynchronicity, and as we will see later, sometimes TPL even chooses to use sequential versions of a query rather than a PLinq one, if it is analysed and deemed to be a better choice.
These areas as well as the normal cancellation/exception handling will be covered in the remainder of this article.
Important Note Before We Start
I am running these samples on a 2 core laptop, and sometimes for the benefit of the screen shots, I specifically choose small data sets, which may not show the best timing, but it does not affect how the TPL code should be written. So you will have to bear with me on this small misgiving.
As with regular Linq, PLinq is mainly achieved using extension methods. Here is a list of the most common extension methods that you may need to use:
| Extension Method | Description |
AsParallel() | Used to specify that you want a datasource to be queried asynchronously
http://msdn.microsoft.com/en-us/library/system.linq.parallelenumerable.asparallel.aspx |
WithExecutionMode() | Sets the ExecutionMode of the query, which can be one of the following enum values
Default
This is the default setting. PLINQ will examine the query's structure and will only parallelize the query if it will likely result in speedup. If the query structure indicates that speedup is not likely to be obtained, then PLINQ will execute the query as an ordinary LINQ to Objects query.
ForceParallelism
Parallelize the entire query, even if that means using high-overhead algorithms. Use this flag in cases where you know that parallel execution of the query will result in speedup, but PLINQ in the Default mode would execute it as sequential.
http://msdn.microsoft.com/en-us/library/dd642145.aspx |
AsOrdered() | Enables treatment of a data source as if it was ordered, overriding the default of unordered |
WithDegreeOfParallelism() | Sets the degree of parallelism to use in a query. Degree of parallelism is the maximum number of concurrently executing tasks that will be used to process the query |
WithMergeOptions() | Sets the merge options for this query, which specify how the query will buffer output |
WithCancellation() | Sets the System.Threading.CancellationToken to associate with the query |
These should help you get to grips with PLinq and we shall be seeing some more of these in action throughout the rest of the article.
Demo Project Name: SimpleParrallelLinq
Standard Linq Scenario
Let's start with a basic example, shall we. This demo code shown below has 3 scenarios - it uses standard (sequential) Linq which is as follows:
IEnumerable<double> results = StaticData.DummyRandomIntValues.Value
.Select(x => Math.Pow(x, 2));
foreach (int item in results)
{
Console.WriteLine("Result is {0}", item);
}
This is all pretty familiar I hope, nothing to really say there except that the data source is a common data source that is used through all the demos used in this article, you will find this data in the ParallelLinq.Common project in the attached solution.
Possibly PLinq Scenario
So how do we specify that we want to run something as PLinq, well it is actually quite simple, you just need to use the AsParallel() extension method on the DataSource, this is quite important, there is a world of difference between:
someDataSource.AsParallel()
and:
(from x in someDataSource where x.Age > 3 select x).AsParallel()
The first one will attempt to run using PLinq, whilst the second example will run the query sequential, and then apply AsParallel() which is incorrect. So just be careful about that one, the AsParallel() needs to go on the data source in a PLinq query.
So anyway, now that you know what makes a PLinq query a PLinq query, let's continue to look at our first example of one.
This next scenario could be run using Plinq or it may be run using sequential Linq?
var results2 = StaticData.DummyRandomIntValues.Value.AsParallel()
.Select(x => Math.Pow(x, 2));
foreach (int item in results2)
{
Console.WriteLine("Result is {0}", item);
}
Huh, how is that, we are specified AsParallel() in the correct place just like you told us to, what gives. Well, the thing is that just because we specify AsParallel(), that does not necessarily mean that the query will be run in parallel. What actually happens is that TPL will analyze the query, and it will determine if the query would be better run as a sequential query or as a parallel one. That is why it may not run asynchronously.
There is however a programmatic way that we can for a PLinq query to be truly parallel, which is shown next.
Truly Parrallel PLinq Scenario
By specifying some more extension methods, we can control more of what TPL offers for PLinq. By adding a...
WithExecutionMode(ParallelExecutionMode.ForceParallelism)
... we are able to say that we don't care what the TPL analysis phase thinks, we know better, and we want this query run Parallel please.
Here is an example:
var results3 = StaticData.DummyRandomIntValues.Value
.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.Select(x => Math.Pow(x, 2));
foreach (int item in results3)
{
Console.WriteLine("Result is {0}", item);
}
Anyway, here is the result of running these 3 simple scenarios:
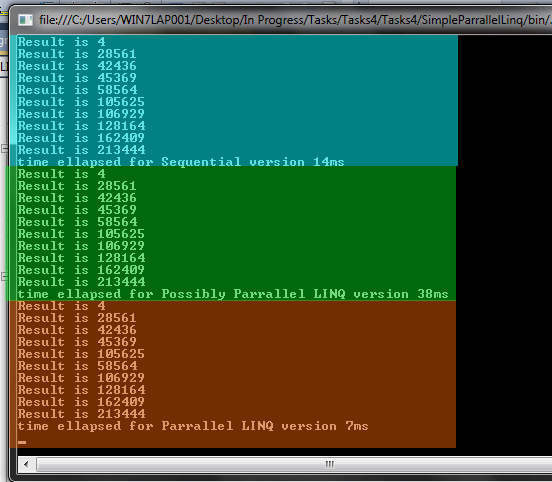
As I stated above, I sometimes use small data sets for the sake of the demos, so these results may look different if you apply large data sets, and more cores.
Demo Project Name: SimpleOrdering
By default, PLinq will not preserve ordering when it is actually running in asynchronous mode (which may not be at all, as I just explained). but assuming it is Async, how do we get it to preserve ordering of the elements that were in the original data source. This is easily achieved using the AsOrdered() extension method, which is shown below.
This example shows a sequential standard Linq query, then a PLinq (asynchronous), and then another PLinq query which has AsOrdered() set on it. Notice that only the sequential and AsOrdered() Plinq queries preserve order.
So if order is important to you, just use AsOrdered().
ManualResetEventSlim mre = new ManualResetEventSlim();
IEnumerable<int> results1 = StaticData.DummyOrderedIntValues.Value
.Select(x => x);
foreach (int item in results1)
{
Console.WriteLine("Sequential Result is {0}", item);
}
mre.Set();
mre.Wait();
mre.Reset();
IEnumerable<int> results2 = StaticData.DummyOrderedIntValues.Value.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.Select(x => x);
foreach (int item in results2)
{
Console.WriteLine("PLINQ Result is {0}", item);
}
mre.Set();
mre.Wait();
mre.Reset();
IEnumerable<int> results3 = StaticData.DummyOrderedIntValues.Value.AsParallel().AsOrdered()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.Select(x => x);
foreach (int item in results3)
{
Console.WriteLine("PLINQ AsOrdered() Result is {0}", item);
}
Here is a screen shot of running:

Demo Project Name: ParallelRange
When using standard Linq, it is quite common to use Range projection to obtain a range of values. PLinq also provides a way of doing this, which is shown as follows:
IEnumerable<int> results = (from i in ParallelEnumerable.Range(0, 100).AsOrdered() select i);
foreach (int item in results)
{
Console.WriteLine("Result is {0}", item);
}
Which when run looks like this:
In this example, I am preserving the ordering using the ParallelQuery.AsOrderered(..) extension method.
Handling exceptions in PLinq is not that different to what we have seen for exception handling in the previous articles in the series, we simply need to use a try/catch and make sure to catch AggregateException (and possibly OperationCancelledException), or use any of the Exception handling methods discussed in the first article. I typically use try/catch as it's what I use elsewhere when not using TPL.
With PLinq, the really important part is to use the try/catch around where you enumerate or use your PLinq results.
Now I am going to present 3 different scenarios, all using a data source of 150 Person objects, here and briefly discuss what happens with each, as you may sometimes be surprised by the results you get. I was quite surprised with some of the results and had to ask a friend Steve Soloman AKA Steve "The Thread" to have a look and together, we drew some conclusions which are outlined in the 3 scenarios below.
Using A List<T> Data Source
IEnumerable<Person> results1 =
StaticData.DummyRandomPeople.Value.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.WithDegreeOfParallelism(2)
.WithMergeOptions(ParallelMergeOptions.NotBuffered)
.Select(x =>
{
if (x.Age >= 100)
throw new InvalidOperationException(
"Can only accept items < 100");
else
return x;
});
try
{
foreach (Person item in results1)
{
Console.WriteLine("Result is {0}", item);
}
}
catch (AggregateException aggEx)
{
foreach (Exception ex in aggEx.InnerExceptions)
{
Console.WriteLine(string.Format("PLinq over List<T> caught exception '{0}'",
ex.Message));
}
}
The first scenario uses a List<Person> objects as a data source. As we are using a List<T>, PLinq knows how many items we are going to have to query, so it more than likely will use a default partitioner (where the data source is processed in chunks that the partitioner decides upon), so we end up with a result something like this (results may vary on your machine):
Using An IEnumerable<T> Data Source
The next scenario using a IEnumerable<Person>:
IEnumerable<Person> results2 =
StaticData.DummyRandomPeopleEnumerable().AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.WithDegreeOfParallelism(2)
.WithMergeOptions(ParallelMergeOptions.NotBuffered)
.Select(x =>
{
if (x.Age >= 100)
throw new InvalidOperationException(
"Can only accept items < 100");
else
return x;
});
try
{
foreach (Person item in results2)
{
Console.WriteLine("Result is {0}", item);
}
}
catch (AggregateException aggEx)
{
foreach (Exception ex in aggEx.InnerExceptions)
{
Console.WriteLine(string.Format("PLinq over IEnumerable<T> caught exception '{0}'",
ex.Message));
}
}
The thing with this one, is that because we do NOT specify AsOrdered() PLinq does not attempt to maintain any order, and also since the data source is Enumerable<Person>, which the eagle eyed among you will notice aint no definitive length list, As such, PLinq does not know how many items there are in the data source without enumerating, so cannot use partitioning, and must enumerate ALL the results, so this time we get a totally different output of something like the following (results may vary on your PC):
Using An IEnumerable<T> Data Source Which We Then Use AsOrdered()
The last scenario I wanted to show was using a IEnumerable<Person> but this time specifying the AsOrdered() clause, which should force PLinq to preserve ordering.
IEnumerable<Person> results3 =
StaticData.DummyRandomPeopleEnumerable().AsParallel()
.AsOrdered()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.WithMergeOptions(ParallelMergeOptions.Default)
.WithDegreeOfParallelism(2)
.Select(x =>
{
if (x.Age >= 100)
throw new InvalidOperationException(
"Can only accept items < 100");
else
return x;
});
try
{
foreach (Person item in results3)
{
Console.WriteLine("Result is {0}", item);
}
}
catch (AggregateException aggEx)
{
foreach (Exception ex in aggEx.InnerExceptions)
{
Console.WriteLine(string.Format("PLinq over IEnumerable<T>
using AsOrdered() caught exception '{0}'",
ex.Message));
}
}
The thing is with this, is that, behind the scenes Task(s) are still uses, TPL will do the work in Task(s), then get the Task.Result from each Task (which is a special Trigger method that will cause AggregateExceptions to be observed), then the combined Task.Result(s) are combined into an ordered result set. But as we are using Task(s) behind the scenes and also using Task.Result, we expect to see AggregateExceptions sooner, so let's see the results:
It's a murky world for sure... But as long as you remember that TPL uses Tasks behind the scenes, you should be ok.
Demo Project Name: Cancellation
I have done 3 previous articles on TPL now, and in each one of them, I have discussed how to use CancellationTokens to cancel some TPL related feature, so by now, I am going to assume you are familiar with how a CancellationToken works.
The interesting thing to note is how you register a CancellationToken with a PLinq query, this is easily achieved using the .WithCancellation(tokenSource.Token) extension method that was shown in the table of extension methods above.
Here is a small example. In this example, we create a new PLinq query, which uses the .WithCancellation(tokenSource.Token) extension method, we then start a Task, which will cancel the PLinq query after some time. We must obviously ensure to catch OperationCancelledException, and AggregateException as is typical when working with TPL.
Here is the full code listing:
CancellationTokenSource tokenSource = new CancellationTokenSource();
IEnumerable<double> results =
StaticData.DummyRandomHugeIntValues.Value
.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.WithCancellation(tokenSource.Token)
.Select(x => Math.Pow(x,2));
Task.Factory.StartNew(() =>
{
Thread.Sleep(500);
tokenSource.Cancel();
Console.WriteLine("Cancelling");
});
try
{
foreach (int item in results)
{
Console.WriteLine("Result is {0}", item);
}
}
catch (OperationCanceledException opcnclEx)
{
Console.WriteLine("Operation was cancelled");
}
catch (AggregateException aggEx)
{
foreach (Exception ex in aggEx.InnerExceptions)
{
Console.WriteLine(string.Format("Caught exception '{0}'",
ex.Message));
}
}
And here is a demo of it all running:
Demo Project Name: CustomPartitioning
To parallelize an operation on a data source, one of the essential steps is to partition the source into multiple sections that can be accessed concurrently by multiple threads. PLINQ and the Task Parallel Library (TPL) provide default partitioners that work transparently when you write a parallel query or ForEach loop. For more advanced scenarios, you can plug in your own partitioner.
In the last article (Parallel For Partitioning), I talked about how using a custom partitioner could possibly be used to speed to up parallel for/foreach loops when there was a small workload delegate. PLinq also supports partitioning and there is a good MSDN article on this which talks about the different sorts of partitioning that one can use.
Here is the link: http://msdn.microsoft.com/en-us/library/dd997411.aspx
For the demo app for this project, I created a simple static partitioner (by inheriting from Partitioner<T>) which splits the data source into n-many partitioned chunks, where the partitionCount is specified by TPL itself, and is made available to my custom partitioner via overriding the Partitioner<T> method
public override IList<IEnumerator<T>> GetPartitions(int partitionCount)
Here is the full code to create a simple custom partitioner for PLinq (more than likely this offers no benefit over using the standard PLinq partitioner, but it does show you how to create you own custom partitioner).
public class SimpleCustomPartitioner<T> : Partitioner<T>
{
private T[] sourceData;
public SimpleCustomPartitioner(T[] sourceData)
{
this.sourceData = sourceData;
}
public override bool SupportsDynamicPartitions
{
get
{
return false;
}
}
public override IList<IEnumerator<T>> GetPartitions(int partitionCount)
{
IList<IEnumerator<T>> partitioned = new List<IEnumerator<T>>();
int itemsPerPartition = sourceData.Length / partitionCount;
for (int i = 0; i < partitionCount - 1; i++)
{
partitioned.Add(GetItemsForPartition(i * itemsPerPartition,
(i + 1) * itemsPerPartition));
}
partitioned.Add(GetItemsForPartition((partitionCount - 1) *
itemsPerPartition, sourceData.Length));
return partitioned;
}
private IEnumerator<T> GetItemsForPartition(int start, int end)
{
for (int i = start; i < end; i++)
yield return sourceData[i];
}
}
Here is small demo of how to use this partitioner. This code has 3 scenarios in it:
- Sequential Linq
- Using Plinq (which uses default partitioner, as we have an array of items, TPL and PLinq is able to use a default partitioner)
- Using PLing with custom partitioner (which as I say, is likely to be no better than the default PLinq partitioner that TPL provides)
Anyway, here is the code:
int[] sourceData = StaticData.DummyOrderedLotsOfIntValues.Value;
ManualResetEventSlim mre = new ManualResetEventSlim();
List<string> overallResults = new List<string>();
Stopwatch watch1 = new Stopwatch();
watch1.Start();
IEnumerable<double> results1 =
sourceData.Select(item => Math.Pow(item, 2));
int visited1 = 0;
foreach (double item in results1)
{
Console.WriteLine("Result is {0}", item);
visited1++;
}
watch1.Stop();
overallResults.Add(string.Format("Visited {0} elements in {1} ms",
visited1.ToString(), watch1.ElapsedMilliseconds));
mre.Set();
mre.Wait();
mre.Reset();
Stopwatch watch2 = new Stopwatch();
watch2.Start();
IEnumerable<double> results2 =
sourceData.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.Select(item => Math.Pow(item, 2));
int visited2 = 0;
foreach (double item in results2)
{
Console.WriteLine("Result is {0}", item);
visited2++;
}
watch2.Stop();
overallResults.Add(string.Format("PLINQ No Partioner Visited {0} elements in {1} ms",
visited2.ToString(), watch2.ElapsedMilliseconds));
mre.Set();
mre.Wait();
mre.Reset();
SimpleCustomPartitioner<int> partitioner =
new SimpleCustomPartitioner<int>(sourceData);
Stopwatch watch3 = new Stopwatch();
watch3.Start();
IEnumerable<double> results3 =
partitioner.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.Select(item => Math.Pow(item, 2));
int visited3 = 0;
foreach (double item in results3)
{
Console.WriteLine("Result is {0}", item);
visited3++;
}
watch3.Stop();
overallResults.Add(string.Format("PLINQ With Custom Partioner Visited {0} elements in {1} ms",
visited3.ToString(), watch3.ElapsedMilliseconds));
foreach (string overallResult in overallResults)
{
Console.WriteLine(overallResult);
}
Console.ReadLine();
And here are the results of all this running:
It can be seen that the sequential version did take longer, but the other 2 PLinq scenarios, there really is not much in it, which is not really that surprising, I mean I would expect the guys that wrote TPL and PLinq to have come up with a default partitioner which is at least as good as one that I have come up with, and it turns out they have. The one I have come up with came up better in this screen shot, but if it were to be run again, this may not be the case at all.
Anyway, the point is that this code shows you how to write your own partitioner, which I now hope you know how to write.
Demo Project Name: CustomAggregation
Now when using standard sequential Linq, it is pretty easy to use aggregate extension methods, we can just do something like this, job done:
int sequentialResult = (from x in peopleData where x.Age gt; 50 select x).Count();
But this would be pretty hard to do when we have split our datasource queries up into small partitions, wouldn't it. Well yeah, if we had to hand code all this, and handle the synchronization of shared objects ourselves and manage the individual Tasks, it would be painful.
Luckily, we don't, TPL provides a way of doing this, which is similar to using Thread Local Storage which I talked about last time. Let's see the same example that would work for a truly parallel PLinq, running using many Tasks.
Here is the code that would do the same as the sequential Linq aggregate above:
int plinqResult =
peopleData.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.WithDegreeOfParallelism(2)
.Aggregate(
0,
(subtotal, person) => subtotal += (person.Age > 50) ? 1 : 0,
(total, subtotal) => total + subtotal,
It is obviously a little bit more complicated, but we just start with an initial value, and then process things in chunks, which are brought together to form the end result of our custom aggregate, which in this example is an Int, which is the amount of Person objects in the data source whose Age property value is currently holding a value > 50. This particular demo data source has 150 Person objects, with Age starting at 1-150;
And just to prove that no fowl play is at hand, here is a screen shot of the results.
That's It For Now
That is all I wanted to say in this in this article. I hope you liked it, and want more. If you did like this article, and would like more, could you spare some time to leave a comment and a vote. Many thanks!
Hopefully, see you at the next one.

